Agent入门
教程大纲:
1. agent llm workflow概念区别 + agent的技术介绍
2. 国内大龙虾 的使用教程(下载 连接大模型 配置skills MCPs multi-agent配置与使用)
3. ClaudeCode 的使用教程(下载 配置大模型 下载并使用 “CLI + skills”的组合)

1. 概念区分
| 维度 | LLM | WorkFlow | Agent |
|---|---|---|---|
| 本质 | 一组训练出来的权重文件(数十亿个参数),运行时这些参数驱动 Transformer 网络进行概率预测 | 一套预先定义好的执行流程(状态机/流程图) | LLM + 工具 + 记忆 + 规划机制组成的自主执行系统 |
| 核心 | 输入 Prompt -> 生成答案 | 开发者提前定义流程,LLM按照流程执行 | LLM自主决定下一步行动 |
1.1. 快速体验 LLM
- 选择模型 并 下载权重文件
预期结构:
gemma/
├── config.json
├── tokenizer.json
├── generation_config.json
├── model.safetensors
└── ...
- 安装依赖 并 加载模型
pip install transformers torch accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "./gemma"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto"
)
- have a try
prompt = "广东财经大学的校史?"
inputs = tokenizer(
prompt,
return_tensors="pt"
).to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=50
)
print(
tokenizer.decode(
outputs[0],
skip_special_tokens=True
)
)
1.2. 快速体验 WorkFlow
- 安装依赖
pip install langgraph langchain langchain-openai python-dotenv
- 定义节点
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from typing import TypedDict, Optional
import os
from dotenv import load_dotenv
# ========== 1. 初始化 LLM ==========
load_dotenv()
llm = ChatOpenAI(
api_key=os.getenv("API_KEY"),
base_url="https://api.deepseek.com",
model="deepseek-v4-pro",
temperature=0.2
)
# ========== 2. 状态定义 ==========
class ChainState(TypedDict):
task: str
draft: Optional[str]
corrected: Optional[str]
polished: Optional[str]
# ========== 3. Agent Prompt ==========
write_agent = ChatPromptTemplate.from_messages([
("system", "你是写作智能体,只负责生成初稿,不要解释。"),
("user", "{task}")
]) | llm
correct_agent = ChatPromptTemplate.from_messages([
("system", "你是纠错智能体,只修正语法、逻辑和错别字,不扩写。"),
("user", "{draft}")
]) | llm
polish_agent = ChatPromptTemplate.from_messages([
("system", "你是润色智能体,只提升表达质量和专业度,不改变意思。"),
("user", "{corrected}")
]) | llm
# ========== 4. Agent Node ==========
def writer_node(state: ChainState):
print("\n✍️【Writer Agent】生成初稿中...")
res = write_agent.invoke({"task": state["task"]})
return {"draft": res.content.strip()}
def correct_node(state: ChainState):
print("\n🧹【Corrector Agent】纠错中...")
res = correct_agent.invoke({"draft": state["draft"]})
return {"corrected": res.content.strip()}
def polish_node(state: ChainState):
print("\n✨【Polisher Agent】润色中...")
res = polish_agent.invoke({"corrected": state["corrected"]})
return {"polished": res.content.strip()}
- 构建工作流
# ========== 5. 构建链式 LangGraph ==========
workflow = StateGraph(ChainState)
workflow.add_node("writer", writer_node)
workflow.add_node("corrector", correct_node)
workflow.add_node("polisher", polish_node)
# 链式 Pipeline
workflow.add_edge(START, "writer")
workflow.add_edge("writer", "corrector")
workflow.add_edge("corrector", "polisher")
workflow.add_edge("polisher", END)
app = workflow.compile()
流程图:

- have a try
# ========== 6. 运行 ==========
if __name__ == "__main__":
init_state = {
"task": "撰写一篇150字左右的介绍文,说明LangGraph多智能体的核心优势,适合技术初学者阅读",
"draft": None,
"corrected": None,
"polished": None,
}
result = app.invoke(init_state)
print("\n" + "=" * 90)
print("📊 链式多智能体 Pipeline 最终结果")
print("=" * 90)
print("\n📝 初稿:\n", result["draft"])
print("\n✅ 纠错:\n", result["corrected"])
print("\n✨ 润色:\n", result["polished"])
print("=" * 90)
1.3. 快速体验 Agent
- 安装依赖
pip install langgraph langchain langchain-openai python-dotenv
- 定义 智能体
from typing import TypedDict, Optional
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
import os
from dotenv import load_dotenv
# ================== 初始化环境 ==================
load_dotenv()
llm = ChatOpenAI(
api_key=os.getenv("API_KEY"),
base_url="https://api.deepseek.com",
model="deepseek-chat",
temperature=0.3
)
# ================== 状态定义 ==================
class TaskState(TypedDict):
task: str
research: Optional[str]
draft: Optional[str]
code: Optional[str]
math: Optional[str]
next_agent: Optional[str]
result: Optional[str]
round_count: int # Supervisor 执行轮次
supervisor_thoughts: Optional[str] # 打印 LLM 思考过程
MAX_ROUNDS = 3
# ================== sub-agent ==================
research_agent = ChatPromptTemplate.from_messages([
("user", "请调研以下任务的背景信息,整理成条列要点,中文输出:{task}")
]) | llm
writer_agent = ChatPromptTemplate.from_messages([
("user", "根据以下信息撰写中文技术文章或说明文:{research}")
]) | llm
code_agent = ChatPromptTemplate.from_messages([
("user", "请根据以下任务生成 Python 示例代码:{task}")
]) | llm
math_agent = ChatPromptTemplate.from_messages([
("user", "请解决以下数学/逻辑问题,并详细说明过程:{task}")
]) | llm
# ================== 动态 Supervisor 节点 ==================
def supervisor_node(state: TaskState):
new_round = state["round_count"] + 1
# 超过最大轮次,触发兜底
if new_round > MAX_ROUNDS:
print(f"⚠️ 超过最大轮次 {MAX_ROUNDS},触发兜底 → 结束任务")
return {
"round_count": new_round,
"next_agent": "end",
"supervisor_thoughts": "轮次数超过上限,直接结束任务"
}
# 中文提示词,严格约束 LLM
prompt = f"""
你是多智能体系统的主管智能体(Supervisor),负责调度专家智能体,但你不执行任务。请阅读当前任务和已完成状态,并选择下一步最合适的智能体执行。
任务:
{state['task']}
已完成状态:
- 调研: {"已完成" if state.get("research") else "未完成"}
- 写作: {"已完成" if state.get("draft") else "未完成"}
- 编程: {"已完成" if state.get("code") else "未完成"}
- 数学: {"已完成" if state.get("math") else "未完成"}
可调度智能体:
- research_agent:负责调研和整理资料
- writer_agent:负责撰写中文文章或说明文
- code_agent:负责编写 Python 代码
- math_agent:负责数学/逻辑计算与推理
约束:
1. 不能选择已完成的智能体。
2. 必须选择与任务相关的智能体。
3. 如果所有任务完成,返回 "end"。
4. 请在回答中先写出你的“思考过程”,然后在最后一行返回下一步智能体名称(research_agent / writer_agent / code_agent / math_agent / end)。
请用中文完整回答:
"""
res = llm.invoke(prompt)
thoughts = res.content.strip()
last_line = thoughts.splitlines()[-1]
valid_agents = ("research_agent", "writer_agent", "code_agent", "math_agent", "end")
next_agent = next((a for a in valid_agents if a in last_line), "end")
print(f"🧠 主管思考过程:\n{thoughts}\n")
print(f"🧠 主管调度 → {next_agent} (轮次 {new_round})")
return {
"round_count": new_round,
"next_agent": next_agent,
"supervisor_thoughts": thoughts
}
# ================== 员工节点 ==================
def research_node(state: TaskState):
print(">>> Research Agent 执行中...")
try:
res = research_agent.invoke({"task": state["task"]})
result = res.content.strip()
except Exception as e:
result = f"调研失败:{str(e)[:50]}"
# ✅ 正确写法:只返回更新字段
return {
"research": result,
"result": result
}
def writer_node(state: TaskState):
print(">>> Writer Agent 执行中...")
try:
res = writer_agent.invoke({"research": state.get("research","")})
result = res.content.strip()
except Exception as e:
result = f"写作失败:{str(e)[:50]}"
# ✅ 正确写法
return {
"draft": result,
"result": result
}
def code_node(state: TaskState):
print(">>> Code Agent 执行中...")
try:
res = code_agent.invoke({"task": state["task"]})
result = res.content.strip()
except Exception as e:
result = f"代码生成失败:{str(e)[:50]}"
# ✅ 正确写法
return {
"code": result,
"result": result
}
def math_node(state: TaskState):
print(">>> Math Agent 执行中...")
try:
res = math_agent.invoke({"task": state["task"]})
result = res.content.strip()
except Exception as e:
result = f"数学求解失败:{str(e)[:50]}"
# ✅ 正确写法
return {
"math": result,
"result": result
}
# ================== 构建 LangGraph ==================
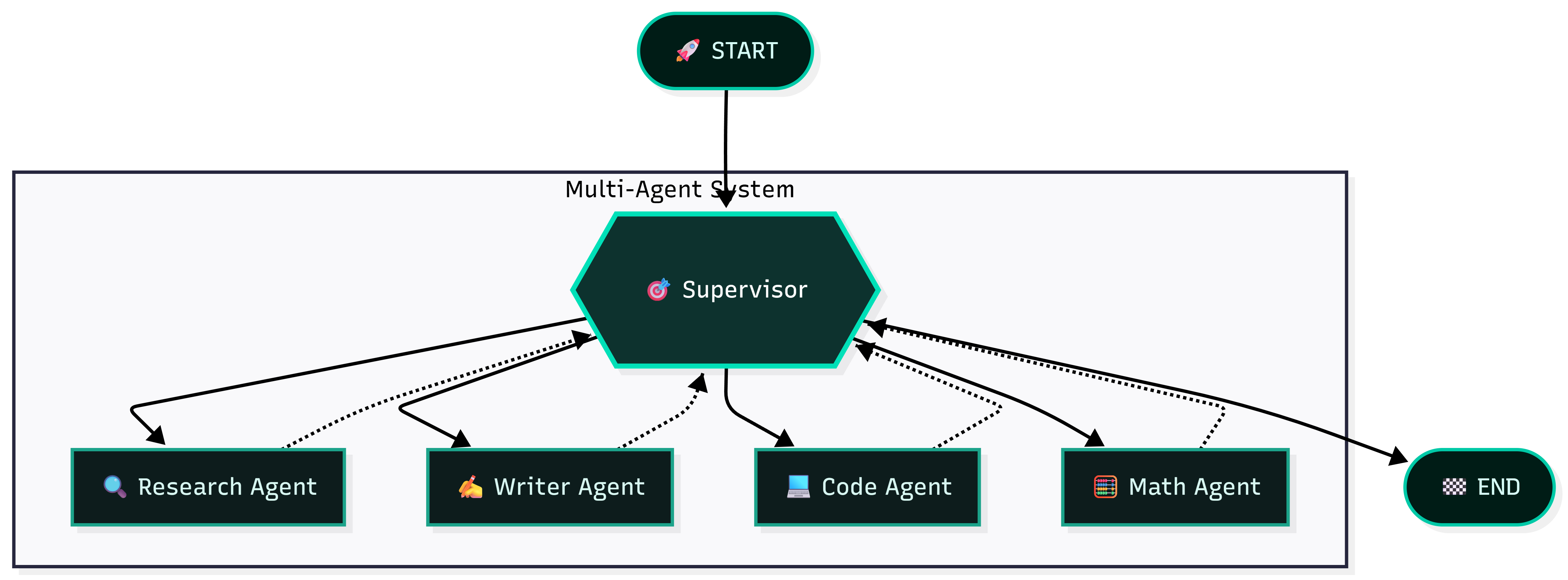
workflow = StateGraph(TaskState)
workflow.add_node("supervisor", supervisor_node)
workflow.add_node("research_agent", research_node)
workflow.add_node("writer_agent", writer_node)
workflow.add_node("code_agent", code_node)
workflow.add_node("math_agent", math_node)
workflow.add_edge(START, "supervisor")
workflow.add_conditional_edges(
"supervisor",
lambda s: s["next_agent"],
{
"research_agent": "research_agent",
"writer_agent": "writer_agent",
"code_agent": "code_agent",
"math_agent": "math_agent",
"end": END
}
)
workflow.add_edge("research_agent", "supervisor")
workflow.add_edge("writer_agent", "supervisor")
workflow.add_edge("code_agent", "supervisor")
workflow.add_edge("math_agent", "supervisor")
app = workflow.compile()
流程图:
- have a try
# ================== 运行示例 ==================
if __name__ == "__main__":
tasks = [
"撰写一篇介绍 LangGraph 多智能体协作的中文文章,面向初学者",
]
for t in tasks:
print("\n" + "="*50)
print(f"任务:{t}")
init_state = {
"task": t,
"research": None,
"draft": None,
"code": None,
"math": None,
"next_agent": None,
"result": None,
"round_count": 0,
"supervisor_thoughts": None
}
result = app.invoke(init_state)
print("\n✅ 最终结果:\n", result["result"])
2. 现代 agent 的发展
┌──────────────────────────────────────────────┐
│ 第一部分:chatbot │
│ Token(Memory) → Prompt Engineering │
└──────────────────────────────────────────────┘
↓
┌──────────────────────────────────────────────────────────────────────────────┐
│ 第二部分:机器 辅助 人 │
│ RAG → Tool Calling → MCP → Context Engineering → Skills → Computer Use(CLI) │
└──────────────────────────────────────────────────────────────────────────────┘
↓
┌────────────────────────────────────────────────────┐
│ 第三部分:人 辅助 机器 │
│ Agent(范式、AICodingAgent) → Harness Engineering │
└────────────────────────────────────────────────────┘
↓
┌──────────────────────────────────┐
│ 第四部分:机器独立 │
│ Workflow → Workspace Agent(IM) │
└──────────────────────────────────┘
3. 技术路线选讲
Tool Calling 线
┌──────────────────────────────────────────────────┐
│ Tool Calling 线 │
│ function calling + API -> MCPs -> CLI + skills │
└──────────────────────────────────────────────────┘
3.1 function calling + API
3.1.1. API示例:
import requests
def search_poi(keywords: str,city: str,api_key: str):
"""直接调用高德地图POI搜索API"""
url = "https://restapi.amap.com/v3/place/text"
params = {
"keywords": keywords,
"city": city,
"key": api_key,
"output": "json"
}
response = requests.get(url,params=params)
data = response.json()
return data
3.1.2. API流程总结:
1. 知道服务器位置(本地/URL)
2. 知道 本系统的输出参数格式 + 服务器需要的输入参数格式 -- 打包
3. 知道 服务器的输出参数格式 + 本系统需要的输入参数格式 -- 解包
3.1.3. API问题总结(用MCPs):
# 一切源于 打包+解包 的苛刻要求
1. 服务器更新(响应格式) -- 你的 API处理代码 也需要变
2. 如果要增加 服务器支持(系统功能扩展) -- 你需要 重新写 新功能的API处理代码
3. 你的代码 不适配类似的系统
3.1.4. API困难分析(用MCPs):
直接使用API的代码看起来很简单,但在实际使用中会遇到几个问题:
1. 首先是Agent 无法自主调用。在我们的 sibuchen-agents 框架中,Agent 通过识别提示词中的工具调用标记(比如[TOOL_CALL:tool_name:arg1=value1])来调用工具。如果我们直接在代码中调用 API,Agent 就失去了自主决策的能力,变成了一个简单的函数调用。 -- 解决方法:封装成工具 -- MCPs(tools 的集合)
2. 参数传递复杂。高德地图的 API 有很多参数,比如 POI 搜索有keywords、city、types、offset、page等十几个参数。如果我们要让 Agent 能够灵活使用这些参数,就需要在提示词中详细说明每个参数的含义和格式,这会让提示词变得非常复杂。 -- 解决方法:构建skills -- 模型上下文协议(MCP,提供tool的上下文信息)
3. 响应解析困难。高德地图 API 返回的是 JSON 格式的数据,结构比较复杂。我们需要编写代码来解析这些数据,提取我们需要的字段。如果 API 的响应格式发生变化,我们就需要修改解析代码。 -- 重点:程序员的开发困难 -- 经典的3个问题 -- 抽象类(MCP)
4. 工具管理混乱。高德地图提供了十几个不同的 API(POI 搜索、天气查询、路线规划等),如果我们为每个 API 都编写一个函数,然后手动注册到 Agent 的工具列表中,代码会变得很冗长。而且当我们想添加新的 API 时,需要修改多个地方。 -- 重点:程序员的开发困难 -- MCPs 对 同系列tools 的封装 -- 类(MCPs)
3.2 MCPs
3.2.1. MCPs代码示例:
from sibuchen_agents.tools import MCPTool
from app.config import get_settings
settings = get_settings()
# 创建MCP工具
mcp_tool = MCPTool(
name="amap_mcp",
command="npx",
args=["-y", "@sugarforever/amap-mcp-server"],
env={"AMAP_API_KEY": settings.amap_api_key},
auto_expand=True
)
3.2.2. MCP 工具调用流程:
流程图:
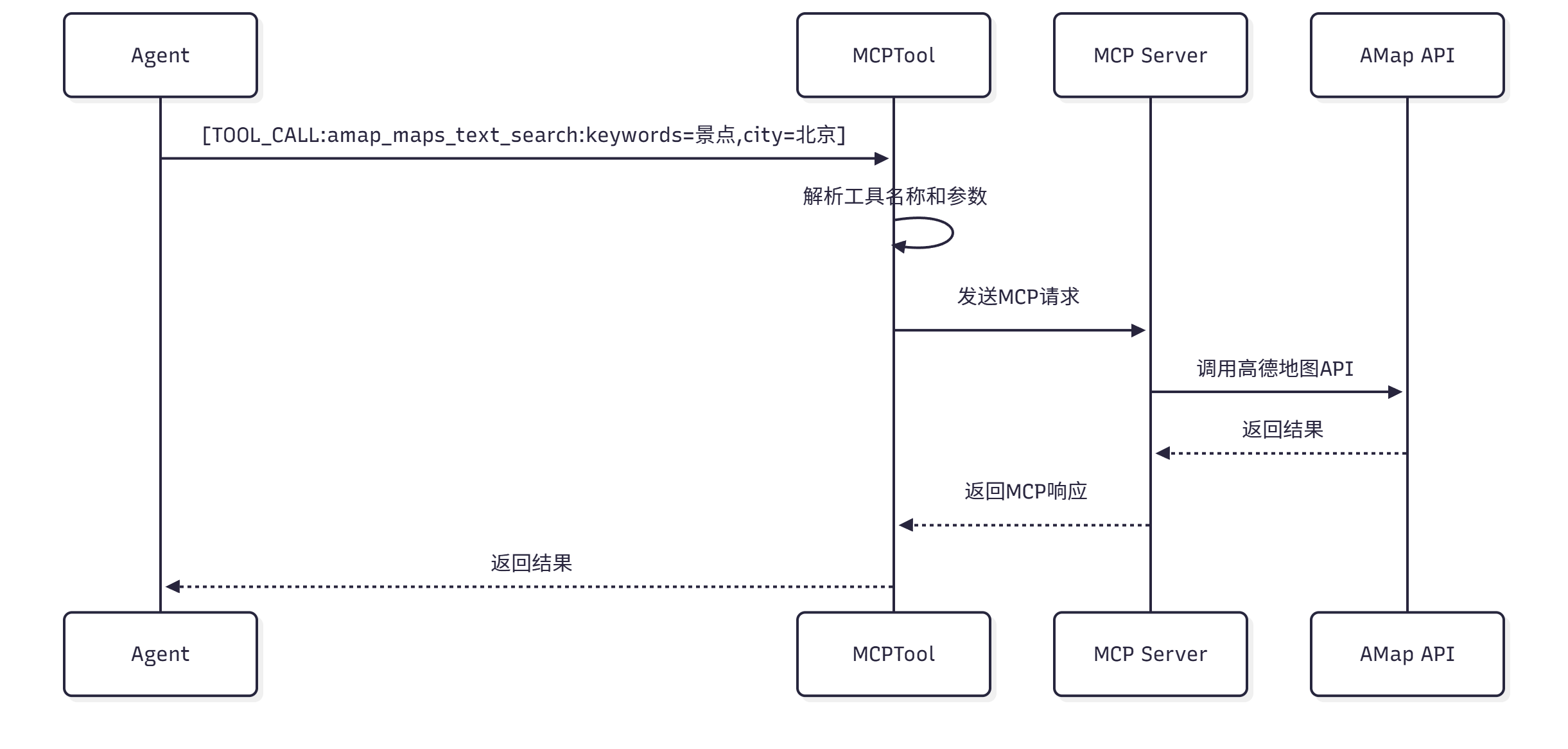
以前:Agent -- API
现在:Agent(mcp_host) -- MCPTool(mcp_client) -- MCPs(mcp_server) -- API(原API服务)
现在:Agent(+ skills) -- TerminalTool -- CLI(下载npx/uvx/... + 运行环境)
具体流程解析:
1. LLM 生成工具调用标记:[TOOL_CALL:amap_maps_text_search:keywords=景点,city=北京]。
2. sibuchen-agents 框架解析这个标记,提取 工具名称 和 参数 ,然后依据 工具名称 调用对应的 Tool对象,传递 参数。
3. Tool 对象是MCPTool自动创建的。接收到参数后,它会构造一个 JSON-RPC 格式的消息,再把调用消息发送给 MCP 服务器(例如,通过 stdin 发送给服务器进程):
{
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": "amap_maps_text_search",
"arguments": {
"keywords": "景点",
"city": "北京"
}
}
}
4. MCP 服务器接收到这个消息,解析参数,运行代码解决问题(很少有) 或者 调用高德地图的 HTTP API 解决问题(主要)。它会构造 HTTP 请求,添加 API 密钥,发送请求,接收响应。
5. 高德地图 API 接收请求,运行代码,并最终返回 JSON 格式的数据。其包含景点列表 、地址、坐标等信息。
6. MCP 服务器解析这些数据,提取关键字段,然后构造响应消息,通过 stdout 返回给MCPTool:
{
"jsonrpc": "2.0",
"result": {
"content": [
{
"type": "text",
"text": "找到以下景点:\n1. 故宫博物院 - 地址:东城区景山前街4号\n2. 天坛公园 - 地址:东城区天坛路\n..."
}
]
}
}
7. MCPTool接收到响应,提取文本内容,通过 sibuchen-agents 架构 将结果返回给 LLM(工具调用结果回注)。
8. LLM 把这个结果作为工具调用的输出,继续生成最终的回复。
这个流程看起来很复杂,但对于 Agent 来说,它只需要知道有一个叫amap_maps_text_search的工具,可以搜索景点。所有的底层细节都被 MCP 协议和MCPTool封装起来了。
3.2.3. MCPs 补充知识
- 三个组件
Host 是 “最终应用”
Client 是 “协议通信模块”
Server 是 “工具提供者”
---
Host
└── Client
↓
Server
举个例子:
(应用)
Cursor
├── UI
├── Agent
├── MCP Client
└── LLM
(外部)
filesystem MCP Server
(组件分析)
Cursor = Host (整个 AI 应用)
其中的 MCP 模块 = Client (Host 内部的 MCP 通信模块)
filesystem = Server (AI 应用 外部的服务)
MCP 本质上是 Client 调用 Server, 而不是 Host 调用 Server
- 五种传输方式 & 两种类型
MCP 协议:规定双方说话的 格式
传输方式:规定双方说话的 渠道
| 传输方式 | 本质 | 适合什么 | 类型 | 部署方式 | 例子 |
|---|---|---|---|---|---|
| Memory | 函数调用 | CS同进程内部 | 本地 MCP Server | 子进程 | 内置的本地 python tool |
| Stdio | 进程管道 | S为本地其它服务 | 本地 MCP Server | 子进程 | filesystem、git、sqlite、terminal、独立的本地 python tool |
| HTTP | 请求响应 | S为远程服务 | 远程 MCP Server | Web服务 | Notion MCP、公司内部 AI 服务、SaaS Tool |
| SSE | 服务端流推送 | 流式输出模式 | 远程 MCP Server | Web服务 | |
| StreamableHTTP | 双向流 | 更高级的实时通信 | 远程 MCP Server | Web服务 |
MCP:
{
"method": "tools/call",
"params": {
"name": "weather",
"arguments": {
"city": "beijing"
}
}
}
Memory:
client -> function() -> server
同一进程内
---
┌─────────────────┐
│ Host │
│ ├── Client │
│ └── Server │
└─────────────────┘
Stdio:
client -> stdin/stdout -> server
Host 启动 Server, 传 JSON
Host进程
└── Client
Server子进程
---
┌────────────────────┐
│ Claude Desktop │
│ └── MCP Client │
└─────────┬──────────┘
│ stdin/stdout
┌─────────▼──────────┐
│ MCP Server │
│ filesystem.py │
└────────────────────┘
HTTP:
client -> HTTP POST -> server
Host 不负责启动 Server, Server 已经运行着
Client 和 Server 机器分离
---
┌─────────────────┐ HTTP ┌─────────────────┐
│ Host │ ───────────────▶ │ MCP Server │
│ └── Client │ │ FastAPI │
└─────────────────┘ └─────────────────┘
SSE(Server-Sent Events):
client -> HTTP -> server -> stream -> client (流式的 HTTP)
结构类似 HTTP, server 持续推送
---
┌─────────────────┐
│ Host │
│ └── Client │
└────────┬────────┘
│ HTTP
▼
┌─────────────────┐
│ MCP Server │
│ 持续stream输出 │
└─────────────────┘
StreamableHTTP:
client -> HTTP + 双向流 -> server (比 SSE 更高级)
长连接 + 双向流
---
┌─────────────────┐ bidirectional stream ┌─────────────────┐
│ Host │ ◀──────────────────▶ │ MCP Server │
│ └── Client │ │ │
└─────────────────┘ └─────────────────┘
代码示例:
# 1. Memory Transport - 内存传输(用于测试)
# 不指定任何参数,使用内置演示服务器
mcp_tool = MCPTool()
# 2.1.1. Stdio Transport - 标准输入输出传输(本地开发)
# 使用命令列表启动本地服务器
mcp_tool = MCPTool(server_command=["python", "examples/mcp_example_server.py"])
# 2.1.2. Stdio Transport with Args - 带参数的命令传输
# 可以传递额外参数
mcp_tool = MCPTool(server_command=["python", "examples/mcp_example_server.py", "--debug"])
# 2.2. Stdio Transport - 社区服务器(npx方式)
# 使用npx启动社区MCP服务器
mcp_tool = MCPTool(server_command=["npx", "-y", "@modelcontextprotocol/server-filesystem", "."])
注意:MCPTool主要用于Stdio和Memory传输。对于HTTP/SSE等远程传输,建议直接使用MCPClient
# 3. HTTP Transport - 连接到远程 HTTP MCP 服务器
client = MCPClient("http://api.example.com/mcp")
# 4. HTTP Transport - 连接到远程 SSE MCP 服务器
client = MCPClient(
"http://localhost:8080/sse",
transport_type="sse"
)
# 5. HTTP Transport - 连接到远程 StreamableHTTP MCP 服务器
client = MCPClient(
"http://localhost:8080/mcp",
transport_type="streamable_http"
)
3.2.4. MCPs使用总结:
mcp_host = agent = 与你交互 的地方
mcp_client = mcp_tool = 系统中获取参数 调用MCPs 返回结果 的地方
mcp_server = mcp_server(本地 - npx/uvx/... - stdio,云端 - url - http) = 外部提供服务(函数) 的地方
额外服务 = mcp_server 利用 http 自行解决 (可能需要 .env 的 API_key)
3.2.5. MCPs的缺点 (用MCPs,CLI+skills)
MCPs -- 重 慢 但是 安全 安全
更多请看 Agent通信协议.md
# 一切源于 模型上下文协议 的 工具上下文
1. MCPs = n个tool,tool 含 工具上下文,工具上下文 = 使用权限 + 输入格式 + 输出格式 + 相关依赖 + ...
2. 工具上下文 = 使用权限 + 输入格式 + 输出格式 + 相关依赖 + ...
3. 以处理照片为例:LLM 要不断选择 MCPs 中的 tools (多轮交互); LLM 只用输出一个 CLI 命令 (一轮交互)
4. LLM只能使用MCPs中的定义:固定输出 固定输入
3.2.6. MCPs 个人看法与思考
- MCPs 很重(一个 MCPs , 加载所有Tools, 一个Tool的内容全部注入上下文) 但是很安全(格式/权限确定)
- MCPs ≈ (skills)插件, tool(全部注入) ≈ skill(渐进式披露)
- " CLI + skill " 的方案 只替代了 " 本地MCPs(传统/新的CLI工具) + 部分远程MCPs " (因为安全性)
| 集合 | 元素 | 格式 | 技术 | 安全(源于技术) |
|---|---|---|---|---|
| API | endpoint | HTTP/JSON | RPC 调用 | Token/鉴权 |
| MCPs | tool | MCP | 上下文注入 + Tool Calling + 全注入 | 细粒度权限 |
| Plugin | skill | Markdown + Assets | Prompt 组织 + 渐进式披露 | 弱权限模型 |
| CLI | command | Shell Command | Process 调用 | 系统权限边界 |
3.3. CLI + skills
3.3.1. 安装CLI
npm install -g @playwright/cli@latest
3.3.2. 安装对应的 skill
playwright-cli install --skills
3.3.3. 启动 ClaudeCode
claude
3.3.4. have a try
/playwright-cli 使用参数--headed --persistent 打开广东财经大学的大数据与人工智能学院的官网,爬取网页的前端设计